whyCTF - HackerEventDB
0x1 程序初探
程序需要一个参数,附件额外给了两个数据库,其中用第一个会输出一些条目信息,第二个则会开启一个彩色的终端Box,提示输入10位密码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
int __fastcall main(int argc, const char **argv, const char **envp)
{
char v3; // r8
__int64 v5; // [rsp+10h] [rbp-10h]
int v6; // [rsp+1Ch] [rbp-4h]
if ( argc == 2 )
{
kb_init(argc, argv, envp);
v6 = open64(argv[1], 0, (char)argv);
if ( v6 >= 0 )
{
v5 = mmap64(0x1337C0DE0000uLL);
if ( v5 == -1 )
{
perror("mmap", 0x1000000LL);
return -1;
}
else
{
j_memset_ifunc(v5, 0LL, 0x1000000LL);
read((unsigned int)v6, v5, 0x1000000LL);
parse(v5);
kb_deinit();
return 0;
}
}
else
{
perror("open", 0LL);
return -1;
}
}
else
{
fprintf(
(_DWORD)stderr,
(unsigned int)"Usage: %s <filename>\n",
(unsigned int)*argv,
(unsigned int)"Usage: %s <filename>\n",
v3);
return 1;
}
}
发现程序会创建一块内存区域,将文件加载进去,地址从0x1337C0DE0000开始。接着进入parse函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
__int64 __fastcall parse(__int64 a1)
{
__int64 result; // rax
int v2; // edx
int v3; // ecx
int v4; // r8d
int v5; // r9d
unsigned int v6; // eax
int v7; // edx
int v8; // ecx
int v9; // r8d
int v10; // r9d
int v11; // edx
int v12; // ecx
int v13; // r8d
int v14; // r9d
int v15; // ecx
int v16; // r8d
int v17; // r9d
char v18[64]; // [rsp+10h] [rbp-160h] BYREF
_DWORD sec_data[65]; // [rsp+50h] [rbp-120h] BYREF
int v20; // [rsp+154h] [rbp-1Ch]
unsigned int data_size; // [rsp+158h] [rbp-18h]
int type; // [rsp+15Ch] [rbp-14h]
unsigned int v23; // [rsp+160h] [rbp-10h]
unsigned int j; // [rsp+164h] [rbp-Ch]
unsigned int i; // [rsp+168h] [rbp-8h]
int ptr; // [rsp+16Ch] [rbp-4h]
if ( (unsigned int)le32(a1) != '\xDE\xAD\xBE\xEF' )
return fwrite("Invalid magic number\n", 1LL, 21LL, stderr);
v23 = le32(a1 + 4);
printf((unsigned int)"\n*** Listing %u hacker camping events ***\n\n", v23 >> 1, v2, v3, v4, v5);
ptr = 8;
for ( i = 0; ; ++i )
{
result = i;
if ( i >= v23 )
break;
type = le32(ptr + a1);
data_size = le32(ptr + 4LL + a1);
ptr += 8; // have read 8 bytes, ptr += 8
mycopy(sec_data, a1 + ptr, data_size);
ptr += data_size;
v6 = (type + 48) << 24;
LOBYTE(v6) = -1;
format_type(v6, v18);
if ( type == 1 )
{
printf((unsigned int)"EVENT: '%s'", (unsigned int)sec_data, v7, v8, v9, v10);
}
else if ( type == 2 )
{
v20 = le32(sec_data);
printf((unsigned int)"YEAR : ", (unsigned int)v18, v11, v12, v13, v14);
for ( j = 0; j < data_size >> 2; ++j )
printf((unsigned int)"%d ", *(_DWORD *)((char *)sec_data + (int)(4 * j)), (unsigned int)sec_data, v15, v16, v17);
putchar(10LL);
}
else
{
printf((unsigned int)"Unknown type %u", type, v7, v8, v9, v10);
}
putchar(10LL);
}
return result;
}
然而这里好像并没有发现执行相关代码的逻辑,连断点都不知道从哪里设置。
但是由于这是一个持续运行的程序,如果能在运行的过程中暂停看RIP的范围,或许能够大致定位代码。 前一阵子学习pwn的时候刚刚知道pwndbg运行过程中,即使一直在期待输入,也能够用Ctrl-C来暂停,从而读取RIP。 在pwndbg中运行,打断点采样,RIP = 0x1337c0de0257,(mmap buffer + 0x257) 接下来查看文件的相关位置: 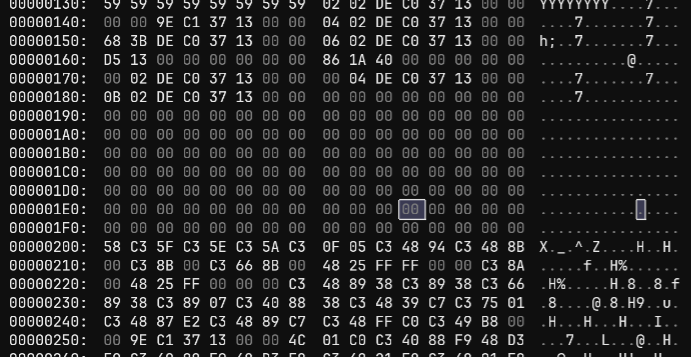 合理怀疑代码是从0x200处开始的,动态调试去0x1337c0de0200找代码。
合理怀疑代码是从0x200处开始的,动态调试去0x1337c0de0200找代码。
0x2 第一层虚拟机
按下 c定义为code, 按下 p 定义函数,发现这里都是一些类似于ROP中的gadget片段 
在这些片段中下断点分析,跟随栈上的运动,发现了其中的运作原理:文件中的数据加载到内存中之后,相当于”栈“,在ret的时候,会从等效栈中取出一个地址,也就相当于跳转到相应地址对应的gadget中。这样下来,“地址”相当于指令码,那些gadget片段定义了可用的指令,相当于广义虚拟机,非常巧妙!
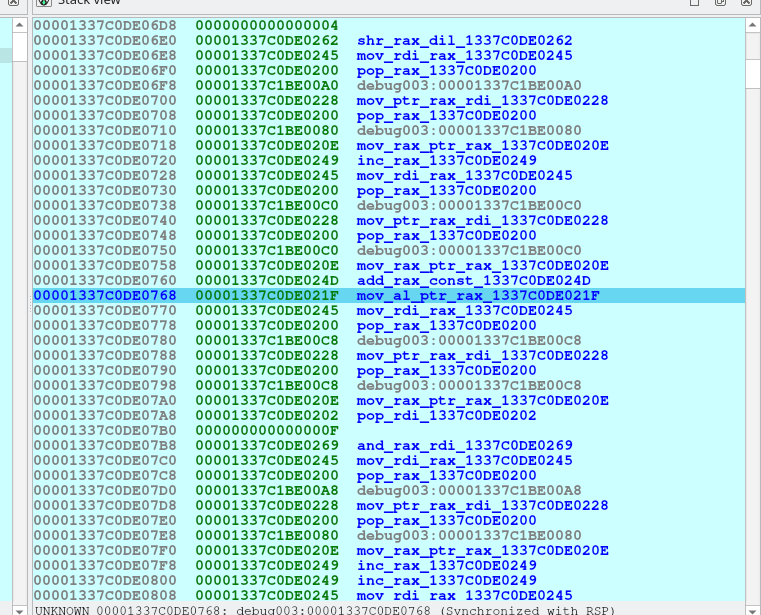
接下来认真分析其中的一些指令:
- pop类型
1
2
3
4
debug003:00001337C0DE0200 pop_rax_1337C0DE0200 proc near
debug003:00001337C0DE0200 pop rax
debug003:00001337C0DE0201 retn
debug003:00001337C0DE0201 pop_rax_1337C0DE0200 endp ;
这种类型的gadget会额外消耗一个操作数,实现从等效栈上加载数据的效果。正常情况下一条地址(也就是虚拟机指令)的下一条还是一个地址,表示连续的两个指令,然而pop指令后面紧跟的是操作数
- xchg类型
1 2 3 4
debug003:00001337C0DE020B xchg_rax_rsp_1337C0DE020B proc near debug003:00001337C0DE020B xchg rax, rsp debug003:00001337C0DE020D retn debug003:00001337C0DE020D xchg_rax_rsp_1337C0DE020B endp
交换
rax和rsp的值,这回导致执行结束的时候,rsp指向的是rax的地址,接着ret跳转到那里。因此xchg等效于正常的jmp指令 - 一些函数
- 其他的指令都比较普通
中途还发现了在一个窗口中按下ESC可以回到上一个位置,这在堆栈中找数据时非常好用。
在研究的时候,在一些gadget下断点运行,偶然发现在0x200之前还有指令执行: 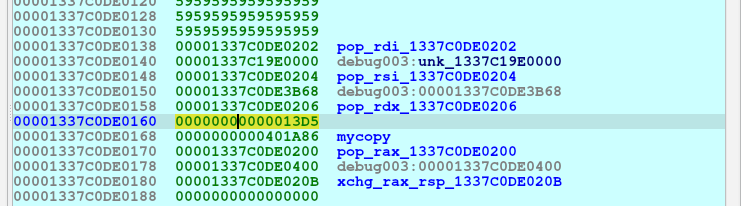 不难发现所做的就是说把一些数据拷贝到
不难发现所做的就是说把一些数据拷贝到 0x1337C19E0000处,可以重点标记一下这个地址。接着pop rax, xxx+0x400, 在进行xchg rax, rsp,相当于跳转到xxx+0x400位置,跟踪过去,发现xxx+0x400开始就是大段的地址,相当于虚拟机代码。
编写解析器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
import struct
file_offset = 0x400
file_end = 0x3B60
def read_qword(f):
global file_offset
data = f.read(8)
file_offset += 8
number = struct.unpack('<Q', data)[0]
return number
instr = {
0x1337C0DE0200:"#mov rax, ",
0x1337C0DE0201:"nop",
0x1337C0DE0202:"#mov rdi, ",
0x1337C0DE0204:"#mov rsi, ",
0x1337C0DE0206:"#mov rdx, ",
0x1337C0DE0208:"syscall",
0x1337C0DE020B:"jmp rax",
0x1337C0DE020E:"mov rax, [rax]",
0x1337C0DE0212:"mov eax, [rax]",
0x1337C0DE0215:"mov ax, [rax]",
0x1337C0DE021F:"mov al, [rax]",
0x1337C0DE0228:"mov [rax], rdi",
0x1337C0DE022C:"mov [rax], edi",
0x1337C0DE022F:"mov [rax], di",
0x1337C0DE0233:"mov [rdi], eax",
0x1337C0DE0236:"mov [rax], dil",
0x1337C0DE023A:"cmp rdi, rax",
0x1337C0DE023E:"jmpnz rdx",
0x1337C0DE0245:"mov rdi, rax",
0x1337C0DE0249:"inc rax",
0x1337C0DE024D:"add rax, vm_code",
0x1337C0DE025B:"shl rax, dil",
0x1337C0DE0262:"shr rax, dil",
0x1337C0DE0269:"and rax, rdi",
0x1337C0DE026D:"add rax, rdi",
0x1337C0DE0271:"add rdi, rax",
0x1337C0DE0275:"mul rdi",
0x1337C0DE0279:"sub rax, rdi",
0x1337C0DE027D:"div rdi",
0x1337C0DE0281:"or rax, rdi",
0x1337C0DE0285:"xor rax, rdi",
0x1337C0DE0289:"call rax_mod_rdi",
0x1337C0DE0297:"movsx rax, ax",
0x1337C0DE029C:"mov rdx, rax",
0x1337C0DE02A0:"mov rsi, rdi",
0x1337C0DE02A4:"int 3",
0x1337C0DE02A6:"call strcat",
0x1337C0DE02C6:"call strlen",
0x1337C0DE02D9:"call func1",
0x1337C0DE032C:"call func2",
0x1337C0DE03C5:"call eax_to_decString_in_r10",
}
with open('./haxx0r_sc3ntz.bin','rb') as f:
f.seek(file_offset)
while file_offset < file_end:
tmp_fileoffset = file_offset
data = read_qword(f)
instr_code = instr.get(data, hex(data))
if instr_code.startswith('#'):
instance_num = read_qword(f)
if hex(instance_num).lower().startswith('0x1337c1be'):
instr_code = instr_code[1:] + 'vm_state+' + hex(instance_num)[-4:]
elif hex(instance_num).lower().startswith('0x1337c19e'):
instr_code = instr_code[1:] + 'vm_code+' + hex(instance_num)[-4:]
else:
instr_code = instr_code[1:] + hex(instance_num)
instr_code = hex(tmp_fileoffset + 0x1337c0de0000) + ': ' + instr_code
print(instr_code)
这里的vm_state和vm_code是分析到后面的几步之后才加上去的。
得到了很长的代码,喂给AI后,得到了一个噩耗——这里存在dispatch逻辑,也就是说,至少还有一层虚拟机!!!
0x3 第二层虚拟机分析
把一整段代码给AI,只能得到一些大致的分析。想要更加精确的分析结果,应该尽可能地将代码按照语义切分成小块。我开始从头开始,寻找第一个 jmp语句,因为它很多时候意味着一段逻辑的终止
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
0x1337c0de0410: mov rax, 0x1fff8
0x1337c0de0418: mov rdi, rax
0x1337c0de0428: mov rax, 0x1337c1be00c8
0x1337c0de0430: mov [rax], rdi
0x1337c0de0440: mov rax, 0xf
0x1337c0de0450: mov rdi, 0x8
0x1337c0de0458: mul rdi
0x1337c0de0468: mov rdi, 0x1337c1be0000
0x1337c0de0470: add rdi, rax
0x1337c0de0480: mov rax, 0x1337c1be00c8
0x1337c0de0488: mov rax, [rax]
0x1337c0de0490: mov [rdi], eax
0x1337c0de04a0: mov rax, 0x1337c1be0080
0x1337c0de04a8: mov rax, [rax]
0x1337c0de04b0: mov rdi, rax
0x1337c0de04c0: mov rax, 0x1337c1be00c0
0x1337c0de04c8: mov [rax], rdi
......
0x1337c0de08e8: mov rdi, 0x1337c0de0900
0x1337c0de08f0: add rax, rdi
0x1337c0de08f8: mov rax, [rax]
0x1337c0de0900: jmp rax
注意目前所有的gadget地址和指令地址都处于0x1337c0??????的位置,然而代码中出现了大量0x1337c1??????的地址,非常可疑。经过AI提醒,将其标记为vm_state(虚拟机的状态结构体,可能包含不同的寄存器)和vm_code(第二层虚拟机的指令),之前的脚本就是修正后的结果
逆向开头一部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
vs->c8 = 0x1fff8
*(vm_code + 0x78) = vs->c8
vs->c0 = vs->80 // PC
vs->c8 = vm_code[vs->c0]
vs->90 = (vs->c8 >> 4) & 0xF
vs->c0 = vs->80
vs->98 = (vs->c8) & 0xF
vs->a0 = (vm_code[PC+1]>>4) &0xF
vs->a8 = (vm_code[PC+1]) & 0xF
vs->b0 = word vm_code[PC+2] (2Byte)
jmp *(0x1337c0de0900 + HI*8)
0x1337c0de0900: 0x1337c0de0980
0x1337c0de0908: 0x1337c0de09a0
0x1337c0de0910: 0x1337c0de19c8
0x1337c0de0918: 0x1337c0de1f38
0x1337c0de0920: 0x1337c0de2418
0x1337c0de0928: 0x1337c0de2960
0x1337c0de0930: 0x1337c0de2bc0
0x1337c0de0938: 0x1337c0de2da0
0x1337c0de0940: 0x1337c0de2f58
0x1337c0de0948: 0x1337c0de2f78
0x1337c0de0950: 0x1337c0de3460
0x1337c0de0958: 0x1337c0de3aa0
0x1337c0de0960: 0x1337c0de0980
0x1337c0de0968: 0x1337c0de0980
0x1337c0de0970: 0x1337c0de0980
0x1337c0de0978: 0x1337c0de0980
发现每次都会读取4个字节,AI猜测vs->80是PC, vs->90和vs->98是第一个字节的高低位,vs->a0和vs->a8是第二个字节的高低位,vs->b0读取了第3、4个字节。
接着根据第一个字节的高位(记为HI)进行跳转,根据这个跳转表,我们能够对程序的分段有大致的了解,HI=0-11各有自己的地址,后面的就和HI=0一样
接下来进入到各段寻找,发现还会根据LO进行二级跳转。
慢慢地确定了vm->a0和vm->a8是两个参数,vm->b0是操作数,vm->b8是状态吗
经过极其漫长的分析后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
R0
R1
R2
R3
R4
R5
R6
R7
R8
R9
R10
R11
R12
R13
R14
R15
PC
HC
LC
B
B
C1
C2
R15 = 0x1fff8
again:
HC = HI(PC)
LC = LO(PC)
A1 = HI(PC+1)
A2 = LO(PC+1)
B = WORD(PC+2)
switch(HC){
case 0, 12, 13, 14, 15:
jmp turn
case 1:
case 2:
case 3:
case 4:
case 5:
case 6:
case 7:
case 8:
case 9:
case 10:
case 11:
}
turn:
PC+=2
// 一级跳表
0x1337c0de0900: HI-1
0x1337c0de0908: HI-2
0x1337c0de0910: HI-3
0x1337c0de0918: HI-4
0x1337c0de0920: HI-5
0x1337c0de0928: HI-6
0x1337c0de0930: HI-7
0x1337c0de0938: HI-8
0x1337c0de0940: HI-9
0x1337c0de0948: HI-10
0x1337c0de0950: HI-11
0x1337c0de0958: HI-12
0x1337c0de0960: HI-1
0x1337c0de0968: HI-1
0x1337c0de0970: HI-1
0x1337c0de0978: HI-1
<HI-1>
jmp label_1
<HI-2>
LO jump table:
0x1337c0de09f8: LO-1
0x1337c0de0a00: LO-2
0x1337c0de0a08: LO-3
0x1337c0de0a10: LO-4
0x1337c0de0a18: LO-5
0x1337c0de0a20: LO-6
0x1337c0de0a28: LO-7
0x1337c0de0a30: LO-8
0x1337c0de0a38: LO-9
0x1337c0de0a40: LO-10
0x1337c0de0a48: 0xdeadbeef
0x1337c0de0a50: 0xdeadbeef
0x1337c0de0a58: 0xdeadbeef
0x1337c0de0a60: 0xdeadbeef
0x1337c0de0a68: 0xdeadbeef
0x1337c0de0a70: 0xdeadbeef
<LO-1>
A1 = A1 + A2
<LO-2>
A1 = A1 - A2
<LO-3>
A1 = A1 * A2
<LO-4>
A1 = A1 / A2
<LO-5>
A1 = A1 & A2
<LO-6>
A1 = A1 | A2
<LO-7>
A1 = A1 ^ A2
<LO-8>
A1 = A1 << A2
<LO-9>
A1 = A1 >> A2
<LO-10>
A1 = A1 % A2
<HI-3> // LC = LO[PC]
switch(LC){
case 0: R[A1] = vm_code[ R[A2] ] 1B
case 1: R[A1] = vm_code[ R[A2] ] 2B
case 2: R[A1] = vm_code[ R[A2] ] 4B
}
<HI-4>
switch(LC){
case 0: vm_code[ R[A2] ] = R[A1] 1B
case 1: vm_code[ R[A2] ] = R[A1] 2B
case 2: vm_code[ R[A2] ] = R[A1] 4B
}
<HI-5>
switch(LC){
case 0: PC += B
case 1:
if(STAT & 0x1)
PC += B
else
PC += 2
case 2:
if(STAT & 0x2)
PC += B
else
PC += 2
default:
}
<HI-6>
call
R15 -= 4
vm_code[R15] = PC + 0x4
PC += B
<HI-7>
ret
<HI-8>
if(R[A2] == R[A1])
STAT = 0x1
else
STAT = 0x2
<HI-9>
0x1337c0de2f58: call func1
<HI-10>
if(LC == 0)
(push)
R15 -= 4
vm_code[R15] = R[A1]
else
(pop)
R[A1] = vm_code[R15]
R15 += 4
<HI-11>
switch(LC){
case 0:
strcat(0x1337c17e0000, vm_code + vs[8*vs->a0]) (vs[8*vs->a0])取出来的是4B指针
case 1:
exit(0)
case 2:
nop
case 3:
write(1, 0x1337c17e0000, strlen(0x1337c17e0000))
case 4:
func2(vs[0], global_buffer + strlen(global_buffer));
case 5:
read(0, &ch, 1);
vs[0] = ch;
}
<HI-12>
hlt
<label_1>:
PC += 2
0x1337c0de3b48: mov rax, label_2
0x1337c0de3b58: jmp rax
接着编写第二层指令解析器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
import struct
file_start = 0x3B68
data_size = 0x13D5
vm_code = b''
R = [0x00 for i in range(16)] # R[0] - R[15]
PC = 0x0
HC, LC = 0x00, 0x00
A1, A2 = 0x00, 0x00
B = 0x0000
C1, C2 = 0x00, 0x00
STAT = 0x00
with open('./haxx0r_sc3ntz.bin','rb') as f:
f.seek(file_start)
vm_code = f.read(data_size)
with open('./backup.bin','wb') as f:
f.write(vm_code)
vm_code += (0x20000 - data_size) * b'\x00'
instr_set = []
while PC < data_size:
R[15] = 0x1fff8 # set RSP
HC = (vm_code[PC]>>4 )&0xF
LC = (vm_code[PC])&0xF
A1 = (vm_code[PC+1]>>4 )&0xF
A2 = (vm_code[PC+1])&0xF
B = vm_code[PC+2] + 256*vm_code[PC+3]
instr = ''
tmpPC = PC
match HC:
case 1:
match LC:
case 0:
instr = 'R{A1} = R{A1} + R{A2}'
case 1:
instr = 'R{A1} = R{A1} - R{A2}'
case 2:
instr = 'R{A1} = R{A1} * R{A2}'
case 3:
instr = 'R{A1} = R{A1} / R{A2}'
case 4:
instr = 'R{A1} = R{A1} & R{A2}'
case 5:
instr = 'R{A1} = R{A1} | R{A2}'
case 6:
instr = 'R{A1} = R{A1} ^ R{A2}'
case 7:
instr = 'R{A1} = R{A1} << R{A2}'
case 8:
instr = 'R{A1} = R{A1} >> R{A2}'
case 9:
instr = 'R{A1} = R{A1} % R{A2}'
case _:
instr = '1?'
case 2:
match LC:
case 0:
instr = 'R{A1} = byte vm_code[ R{A2} ]'
case 1:
instr = 'R{A1} = word vm_code[ R{A2} ]'
case 2:
instr = 'R{A1} = dword vm_code[ R{A2} ]'
case _:
instr = '2?'
case 3:
match LC:
case 0:
instr = 'vm_code[ R{A2} ] = byte R{A1}'
case 1:
instr = 'vm_code[ R{A2} ] = word R{A1}'
case 2:
instr = 'vm_code[ R{A2} ] = dword R{A1}'
case _:
instr = '3?'
case 4:
match LC:
case 0:
instr = 'jmp '+hex(tmpPC + struct.unpack('h', struct.pack('H', B))[0])
PC += 2
case 1:
instr = 'j(STAT & 0x1) '+hex(tmpPC + struct.unpack('h', struct.pack('H', B))[0])
PC += 2
case 2:
instr = 'j(STAT & 0x2)'+hex(tmpPC + struct.unpack('h', struct.pack('H', B))[0])
PC += 2
case _:
instr = '4?'
case 5:
instr = 'call '+hex(PC + struct.unpack('h', struct.pack('H', B))[0])
PC +=2
case 6:
instr ='ret'
case 7:
instr = 'STAT = (R{A1} == R{A2}) ? 1 : 2'
case 8:
if LC == 0:
instr = 'R{A1} = R{A2}'
else:
instr = 'R{A1} = '+hex(B)
PC += 2 # 跳过下一条数据
case 9:
if(LC == 0):
instr = 'push R{A1}'
else:
instr = 'pop R{A1}'
case 10:
match LC:
case 0:
instr = 'strcat(buffer, vm_code + R{A1})'
case 1:
instr = 'exit(0)'
case 2:
instr = 'nop'
case 3:
instr = 'write(1, buffer, strlen(buffer))'
case 4:
instr = 'color_str( edi(char|B|G|R), buffer + strlen(buffer))'
case 5:
instr = 'R0 = getchar()'
case _:
instr = 'A?'
case 11:
instr = 'hlt'
case _:
instr = hex(HC)[-1]+hex(LC)[-1]
PC += 2
prefix = hex(tmpPC)+'\t\t'
instr_set.append(prefix+instr.format(A1=A1, A2=A2, PC=tmpPC, B=B))
if 'ret' in instr:
instr_set.append('\n<{PC}>'.format(PC=hex(PC)))
for instr in instr_set:
print(instr)
解析后得到文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
0x0 jmp 0x2c
0x4 2?
0x6 strcat(buffer, vm_code + R7)
0x8 STAT = (R4 == R0) ? 1 : 2
0xa j(STAT & 0x2)0x10ec
0xe A?
......(data)
<0x2c>
......
(渲染逻辑,很复杂,但是无关)
<0x208>
void generate_texture_data() {
uint8_t* buffer = (uint8_t*)0x2000;
for (int y = 0; y < 8; y++) {
for (int x = 0; x < 40; x++) {
uint8_t* pixel = &buffer[y * 320 + x * 4];
// 生成4个字节的像素数据
uint8_t val1 = complex_transform(x, y, 1) >> 2;
uint8_t val2 = complex_transform(x, y, 0) >> 1;
uint8_t val3 = val2 >> 1;
uint8_t val4 = function_0x6d0(x, y);
pixel[0] = val1;
pixel[1] = val2;
pixel[2] = val3;
pixel[3] = val4;
}
}
}
<0x29a>
0x29a R0 = 0x1122
0x29e R0 = dword vm_code[ R0 ]
0x2a0 R1 = 0x1126
0x2a4 R1 = dword vm_code[ R1 ]
0x2a6 STAT = (R0 == R1) ? 1 : 2
0x2a8 j(STAT & 0x2)0x426
0x2ac R0 = 0x1112
0x2b0 R0 = dword vm_code[ R0 ]
0x2b2 R1 = 0x0
0x2b6 STAT = (R0 == R1) ? 1 : 2
0x2b8 j(STAT & 0x1) 0x426
0x2bc R1 = 0x1
0x2c0 STAT = (R0 == R1) ? 1 : 2
0x2c2 j(STAT & 0x1) 0x2e4
0x2c6 R1 = 0x2
0x2ca STAT = (R0 == R1) ? 1 : 2
0x2cc j(STAT & 0x1) 0x3a8
0x2d0 R1 = 0x3
0x2d4 STAT = (R0 == R1) ? 1 : 2
0x2d6 j(STAT & 0x1) 0x3d2
0x2da R1 = 0x4
0x2de STAT = (R0 == R1) ? 1 : 2
0x2e0 j(STAT & 0x1) 0x3fc
0x2e4 R0 = 0x1188
0x2e8 R1 = 0x0
0x2ec R2 = 0x10
0x2f0 R1 = R1 << R2
0x2f2 R2 = 0xa5ff
0x2f6 R1 = R1 | R2
0x2f8 R2 = 0x50
0x2fc set_data
0x300 R0 = 0x113a
0x304 R1 = 0x5
0x308 call simple_hash
0x30c R1 = 0x1154
0x310 vm_code[ R1 ] = dword R0
0x312 R0 = 0x113a
0x316 R1 = 0x5
0x31a call hash2
0x31e R1 = 0x1154
0x322 R2 = 0x4
0x326 R1 = R1 + R2
0x328 vm_code[ R1 ] = dword R0
0x32a R0 = 0x113a
0x32e R1 = 0x5
0x332 R0 = R0 + R1
0x334 call simple_hash
0x338 R1 = 0x1154
0x33c R2 = 0x8
0x340 R1 = R1 + R2
0x342 vm_code[ R1 ] = dword R0
0x344 R0 = 0x113a
0x348 R1 = 0x5
0x34c R0 = R0 + R1
0x34e call hash2
0x352 R1 = 0x1154
0x356 R2 = 0xc
0x35a R1 = R1 + R2
0x35c vm_code[ R1 ] = dword R0
0x35e R0 = 0x1144
0x362 R1 = 0x1154
0x366 R2 = 0x10
0x36a call memory_compare
0x36e R1 = 0x0
0x372 STAT = (R0 == R1) ? 1 : 2
0x374 j(STAT & 0x1) 0x386
0x378 R0 = 0x1112
0x37c R1 = 0x2
0x380 vm_code[ R0 ] = dword R1
0x382 jmp 0x426
0x386 R0 = 0x113a
0x38a call call rc4_key_schedule
0x38e R0 = 0x4
0x392 R1 = 0x27
0x396 call rc4_crypt
......
<0x428>
void input_buffer_append() {
int ch = getchar();
// 检查EOF
if (ch == 0) {
return; // EOF,直接返回
}
// 获取当前缓冲区状态
uint32_t* length_ptr = (uint32_t*)0x1132;
uint32_t current_length = *length_ptr;
// 计算存储位置并存储字符
uint8_t* buffer = (uint8_t*)0x113a;
buffer[current_length] = (uint8_t)ch;
// 更新长度
(*length_ptr)++;
}
......
<0x44e>
void check_and_reset_buffer() {
uint32_t* length_ptr = (uint32_t*)0x1132;
uint32_t current_length = *length_ptr;
// 检查是否达到10个字符
if (current_length == 10) {
// 重置缓冲区长度
*length_ptr = 0;
// 设置处理完成标志
uint32_t* status_flag = (uint32_t*)0x1112;
*status_flag = 1;
}
}
<0x474>
set_data(R0, R1, R2)
vm_code[0x1122] = 0x0
vm_code[0x1126] = R2
vm_code[0x112a] = R0
vm_code[0x112e] = R1
return
<0x492>
void main_render_function() {
uint32_t frame_counter = vm_code[0x1122];
uint32_t sync_counter = vm_code[0x1126];
// 帧同步检查
if (frame_counter == sync_counter) {
return; // 跳过本帧渲染
}
// 清除背景区域 (35×6 矩形,从(2,5)开始)
fill_rectangle(2, 5, 35, 6, 0x20000000);
// 动态颜色计算
uint32_t anim_seed = vm_code[0x1116];
uint8_t color_seed = lookup_function(anim_seed << 4);
uint32_t source_color = vm_code[0x112e];
uint8_t red = function_0x7e4(source_color & 0xFF, color_seed);
uint8_t green = function_0x7e4((source_color >> 8) & 0xFF, color_seed);
uint8_t blue = function_0x7e4((source_color >> 16) & 0xFF, color_seed);
// 存储计算后的RGB分量
vm_code[0x111e] = red;
vm_code[0x111f] = green;
vm_code[0x1120] = blue;
// 渲染文本
uint32_t text_addr = vm_code[0x112a];
uint32_t text_color = (blue << 16) | (green << 8) | red; // 重新打包RGB
decrypt_and_render_string(2, 8, text_addr, text_color);
// 更新帧计数器
vm_code[0x1122]++;
}
<0x572>
void render_static_ui() {
// 1. 绘制外层背景
fill_rectangle(2, 5, 35, 6, 0x20000000);
// 2. 绘制内层边框
fill_rectangle(3, 6, 33, 4, 0x2e00ff00);
// 3. 显示标题文本
decrypt_and_render_string(2, 5, 0x1164, 0xffffff);
// 4. 绘制输入指示器
int buffer_length = vm_code[0x1132]; // 输入缓冲区长度
for (int i = 0; i < buffer_length; i++) {
int x = 5 + i * 3; // 每个指示器间隔3像素
int y = 7;
fill_rectangle(x, y, 2, 2, 0x23ffffff); // 白色小方块
}
}
<0x64e>
......
<0x6d0>
......
<0x6f0>
uint8_t hash_index_function(uint32_t input1, uint32_t input2) {
uint32_t constant = vm_code[0x1116]; // 动态常数
// 组合输入
uint32_t combined = input1 + input2 + constant;
// 查找表变换
uint8_t transformed = lookup_function(combined & 0xFF);
// 映射到0-39范围
return transformed % 40;
}
<0x706>
uint8_t complex_transform(R0:data, R1:seed_key, R2:shift) {
uint32_t constant = vm_code[0x1116]; // 加载常数
// 第一阶段变换
uint32_t result = data >> 1;
result = result + constant;
result = result ^ seed_key;
result = result << 1;
result = result + constant;
// 条件分支处理
if (shift == 9) {
// 特殊情况:直接进行最终查找
return lookup_function(result);
} else {
// 复杂变换
uint32_t temp = result;
uint32_t shifted_constant = constant >> shift;
uint8_t lookup_result = lookup_function(shifted_constant);
result = (lookup_result + temp) & 0xFF;
return lookup_function(result);
}
}
<0x750>
void decrypt_and_render_string(int x, int y, char* encrypted_str, int color) {
uint32_t* display_buffer = (uint32_t*)0x2000;
int offset = y * 40 + x;
uint32_t* current_pos = &display_buffer[offset];
char* current_byte = encrypted_str;
while (true) {
// 解密当前字节
char decrypted_char = decrypt(*current_byte, (uint32_t)current_byte);
// 检查字符串结束
if (decrypted_char == 0) break;
// 跳过空格字符的渲染
if (decrypted_char != 0x20) {
// 构造像素数据:高8位为字符,低24位为颜色
uint32_t pixel_data = (decrypted_char << 24) | color;
*current_pos = pixel_data;
}
current_byte++; // 下一个加密字节
current_pos++; // 下一个显示位置
}
}
<0x7a8>
uint32_t decrypt(R0:data, R1:key) {
// 1. 构造魔数常量
uint32_t magic = 0xdeadc0de;
// 2. 密钥扩展 (16位扩展为32位)
uint32_t expanded_key = (key << 16) | key;
// 3. 密钥变换
uint32_t transformed_key = magic ^ expanded_key;
// 4. 查表解密
uint8_t table_index = key & 0x3; // 0-3范围
uint8_t table_value = lookup_table[R15 + table_index];
// 5. 最终解密
return data ^ table_value;
}
<0x7e4>
0x7e4 R0 = R0 * R1
0x7e6 R1 = 0xff
0x7ea R0 = R0 / R1
0x7ec ret
<0x7ee>
void fill_rectangle(R0:start_x, R1:start_y, R2:width, R3:height, R4:value) {
int array_base = 0x2000;
for (int y = start_y; y < start_y + height; y++) {
for (int x = start_x; x < start_x + width; x++) {
int offset = (y * 40 + x) * 4;
*(int*)(array_base + offset) = value;
}
}
}
<0x850>
memset_R0(0x2000, len=0x960, val=R0)
<0x860>
uint8_t lookup_function(R0:input) {
uint8_t lookup_table_base = 0x12d5;
uint8_t index = input & 0xFF; // 限制在0-255范围
return vm_code[lookup_table_base + index];
}
<0x874>
R0: buffer ptr
R1: len
hash2(buffer, len)
hash = 0x811c9dc5
for(int i=0; i<len; i++)
hash = hash ^ buffer[i]
hash = hash * 0x1000193
return hash
<0x8be>
uint32_t simple_hash(uint8_t* data, int length) {
uint32_t hash = 0x1505; // 初始种子 (5381)
for (int i = 0; i < length; i++) {
hash = hash * 33 + data[i];
}
return hash;
}
<call rc4_key_schedule>
void rc4_key_schedule(uint8_t* key) {
uint8_t S[256]; // S-box位于地址0x13d5
int key_length = 10; // 固定10字节密钥长度
// 1. 初始化S-box
for (int i = 0; i < 256; i++) {
S[i] = i;
}
// 2. 密钥调度算法
int j = 0;
for (int i = 0; i < 256; i++) {
j = (j + S[i] + key[i % key_length]) % 256;
// 交换S[i]和S[j]
uint8_t temp = S[i];
S[i] = S[j];
S[j] = temp;
}
}
<0x958>
void rc4_crypt(uint8_t* data, int length) {
static uint8_t i = 0, j = 0; // RC4状态变量
uint8_t* S = (uint8_t*)0x13d5; // S-box地址
for (int idx = 0; idx < length; idx++) {
// RC4 PRGA算法
i = (i + 1) % 256;
j = (j + S[i]) % 256;
// 交换S[i]和S[j]
uint8_t temp = S[i];
S[i] = S[j];
S[j] = temp;
// 生成密钥流并加密
uint8_t k = S[(S[i] + S[j]) % 256];
data[idx] ^= k;
}
}
<0x9f2>
......
<0xa50>
void memset_function(void* start_addr, uint8_t value, size_t length) {
memset(start_addr, value, length);
}
<0xa62>
int memory_compare(void* addr1, void* addr2, size_t length) {
uint32_t* ptr1 = (uint32_t*)addr1;
uint32_t* ptr2 = (uint32_t*)addr2;
size_t dword_count = length / 4; // 假设length是4的倍数
for (size_t i = 0; i < dword_count; i++) {
if (ptr1[i] != ptr2[i]) {
return 1; // 不相等
}
}
return 0; // 相等
}
......